Using the genetic code handout, translate the DNA sequence on your handout, and determine the reading frame which contains an ORF (open reading frame). You will turn in your manual translation with the rest of the week 1 materials when they are due.
SIM - Alignment Tool for protein sequences at EXPASY
1. Select the button: User-entered sequence for each sequence window.
2. Give each sequence a short name
3. Paste each of your two protein sequences into the two windows.
4. Change number of alignments to be computed to: 1 --Leave other default settings unchanged
5. Click SUBMIT button.
Exercise 5 - Multiple sequence alignment of protein sequences
Making alignments of related protein sequences is an important technique for a variety of purposes. Alignments show what portions of a molecule are shared between two or more molecules. Alignments are the starting point for determining the relatedness of molecules, and by extension the organisms from which they come.
Parts of a given protein that are highly conserved (that is, unchanged over evolutionary time) in many distantly related organisms are likely to be important functional regions. In other words, that portion of the protein cannot be altered by mutations in the gene encoding it without destroying or reducing the protein's function. Such mutants are selected against and do not survive. Regions of the protein that can change without disrupting protein function will evolve over time and be different in distantly related organisms.
For a molecular biologist, those highly conserved regions of a gene/protein can also be a key to isolating a gene from an organism for which have little or no DNA sequence information, as we will discuss later when we examine a technique known as 'degenerate PCR.'
Some 'proteins of interest'
1. Download sequences to align
Using your newly acquired sequence retrieval skills, find and save the sequences of at least 5 related proteins in FASTA format. Save each of these sequences in a new folder, and name them using the accession number.
For very highly conserved proteins, you can select a wide range of organisms, including animals, plants, fungi - even perhaps bacteria or archea. For other conserved proteins you may wish to restrict yourself to animals or plants or fungi. For most proteins, selecting too closely related a group of sequences will result in an alignment with few differences.
2. Paste all sequences in FASTA format into a single file
In one method of performing a multiple sequence alignment, we must first create a plain text file with all the sequences we wish to align in the FASTA format. Open a word processor window on your computer (and stagger the two windows on the screen so you can easily go back and forth between them). Then paste each sequence into a single text document, with a blank line in between each.
Example FASTA files
3. Rename the sequences
For convenience (given the program we are using), in your sequence collection file, rename each sequence with the species name initials, underscore, and short name. Make sure there are no spaces in the name.
Example: rename the full FASTA description
>gi|132814447|ref|NM_001082971.1| Homo sapiens dopa decarboxylase (aromatic L-amino acid decarboxylase) (DDC), transcript variant 1, mRNA
As:
>Hsa_DDC
4. Run the alignment with ClustalW2.
The program we will use for alignment is ClustalW2 and is found at the EBI website. There are others multiple sequence aligmnent programs available, including on the NCBI website.
Either paste the collected sequences into the large window, or upload the saved file (note that for uploading the file MUST be in a plain text/text only format).
We will use the program default settings, although we may wish to alter two output parameters (in the lower left):
Output format - try a couple different formats to see the possibilities
and
Output order [you may prefer the order in your input file to be retained - if so, change this selection to 'input' vs. the default 'aligned'
Note also that the order in which the sequences are input (that is, the order you have them in your FASTA file) can affect the alignment.
Files you can use for demonstration purposes: Example FASTA files
Exercise 6 - Access the Protein Structure Database, View Structures
1. Go to ENTREZ - Structure
2. Search with one of the following accession numbers:
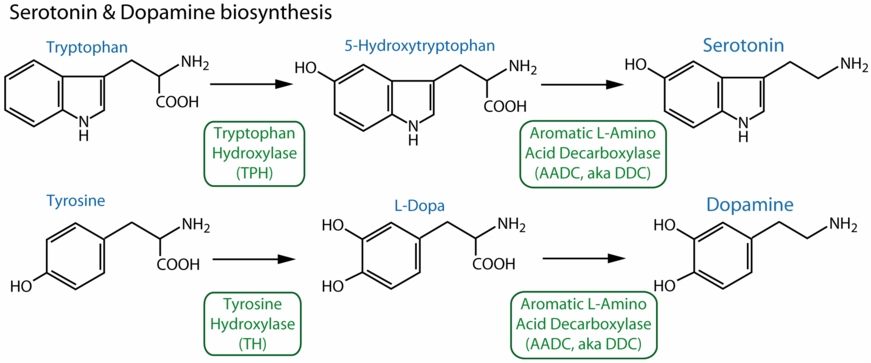
Proteins of interest related to serotonin, dopamine & biopterin synthesis
- 1FB1 - Human GTP Cyclohydrolase I
- 1WPL - Rat GTP Cyclohydrolase I complexed with GFRP
- 1N3S - E. coli GTP Cyclohydrolase I
- 2G64 - C. elegans Pyruvoyl Tetrahydropterin Synthase
- 1B6Z - Rat Pyruvoyl Tetrahydropterin Synthase
- 1OAA - Mouse Sepiapterin Reductase
- 2BD0 - Chlorobium Sepiapterin Reductase
- 1DCH - Rat Pterin dehydratase (PCBD/DCoH)
- 1DHR - Human Dihydropteridine Reductase
- 1JS6 - Pig Dopa Decarboxylase
- 1TOH - Rat Tyrosine Hydroxylase
- 1MLW - Human Tryptophan Hydroxylase
- 2PHM - Human Phenylalanine Hydroxylase
- 2V27 - Colwellia Phenylalanine Hydroxylase
Interesting DNA binding proteins complexed to DNA
- 1L1M - Lac Repressor protein dimer bound to Operator DNA
- 1LMB - Lambda Repressor protein dimer bound to Operator DNA
- 1B8I - Ubx homeodomain protein bound to DNA
- 1MYD - MyoD basic helix-loop-helix (bHLH) protein bound to DNA
- 1YSA - GCN basic leucine zipper (bZIP) protein bound to DNA
- 1R40 - Glucocorticoid receptor protein bound to DNA
- 1AAY - ZIF268 Zinc finger protein bound to DNA
Or, try the protein of your choice, such as the protein you chose for a multiple alignment previously. Note: not all of these proteins may not have crystal structures.
3. Click on the entry, which will take you to a MMDB Structure Summary
4. View structures using FirstGlance in Jmol
Examine the structure of at least two different proteins.
5. Enter a PDB file number and wait for the image to load. Then you can view it in a variety of ways.
Extras - look at conservation of structural features of proteins. Open two windows side by side and compare structures of:
6. Human and E. coli GTP cyclohydrolases
7. Rat and C. elegans Pyruvoyl Tetrahydropterin Synthases
8. Mouse and Chlorobium (bacteria) sepiapterin reductases
9. Various aromatic amino acid hydroxylases
10. Ubx homeodomain and Lambda Cro helix-turn helix proteins bound to DNA
11. A bHLH protein (e.g., GCN) and a bZIP protein (e.g., Fos-Jun heterodimer) bound to DNA
© 2013 Curtis Loer, Dept of Biology, USD. All rights reserved. Simple, hand-coded pages.
{kind=link}