Notes on Phys 272 'Goldilocks Plots': a brief conversation...
Every lab will have at least one modeling plot. To cheat the process, just scroll to the bottom to see what this whole page is building up to.
Good notebook skills involve making plots right there on the quadrille paper especially designed for the very purpose. One can quickly make reasonably neat tables too without a lot of effort, and then proceed to make quick work of a graph, or plot, even while the data is being taken. It helps to work in teams, one person calling out the measurements, another writing things down, or adding data points to the plot, and so forth.
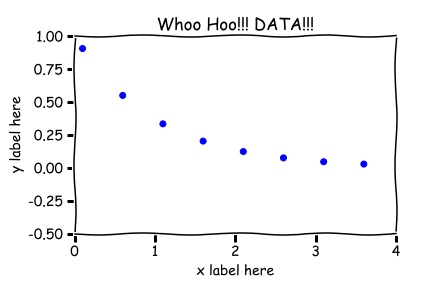
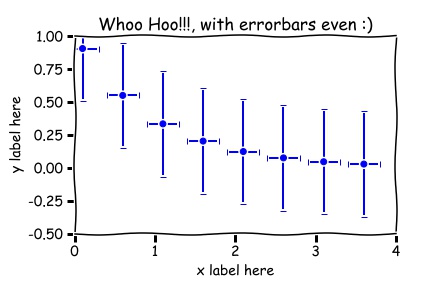
ANY plot will have axes and labels. Plots typically do not have titles in peer reviewed journals. Titles on the displayed plots below were put there for training purposes only (training the instructor that is...who is trying to teach himself something about 'matplotlib' in Python). What if you are observing some quantity decay in time, perhaps some radioactive substance of some sort, and someone calls out the readings of the Geiger-Counter, or a detector records the data and software is used to create a data set, say, and you make the scatter plot, so called, shown below.
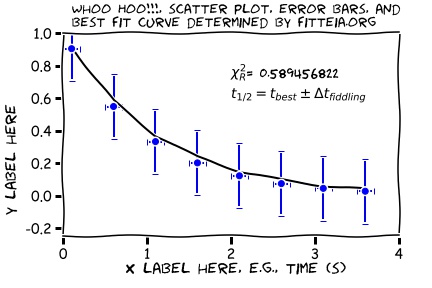
'Goldilocks Analysis'...
But actually this is not quite satisfactory. We don't know how FITTEIA decided the uncertainty in the fitting parameter! So let's take on the responsibility ourselves. Take control of the fitting process by playing with the fitting parameter you care about directly, once the best fit has been determined Fitteia in the following way:- call the fitting parameter obtained by FITTEA, `JUST RIGHT'.
- use the 'Free/Fix' buttons next to the fitting parameter to 'FIX', or adjust (edit), the fitting parameter value so that the new fitting curve is a little 'TOO BIG', that is, above the best fit curve, but still fits within the error bars, more or less. Call this value of the fitting parameter 'TOO BIG'. Then,
- 'Fix' the fitting parameter as just described so that the fitting curve now is a little 'TOO SMALL', that is, the new fitting curve is now under the best fit curve but clips the error bars still (more or less) on the low side of the best fit curve. Call this value of the fitting parameter 'TOO SMALL'.
- Calculate the value of the uncertainty in the fitting parameter to be the difference between values 'TOO BIG' and 'TOO SMALL', divided by 2.
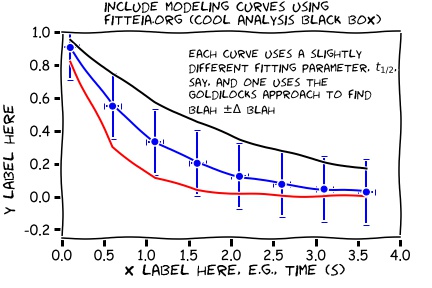
- the difference in principle between the uncertainty in the fitting parameter, and the uncertainty in the measured data points! They will probably even have different units! You need to know both, you cannot really have one without the other, but probably only the uncertainty in the fit will make it into the abstract. Why? Because only this uncertainty quantifies the the goodness of the fit, how well the model and the data agree, something to appeal to, to look at when comparing discrepancies and experimental uncertainties and so forth.
- the most significant digit of the uncertainty here determines the least significant digit of the best value. So, round things, to get just one digit of uncertainty.